MDM: Medical Data Mining
داده کاوی در پزشکیMDM: Medical Data Mining
داده کاوی در پزشکی
سیستم پشتیبانی کشف قانون برای داده های متوالی پزشکی
مقاله: سیستم پشتیبانی کشف قانون برای داده های متوالی پزشکی - مطالعه موردی دیتاست های هپاتیت مزمن (Chronic Hepatitis)
در این مقاله در مورد اینکه پیش پردازش داده ها چگونه باید انجام شود و یک سیستم پشتیبانی کشف قانون (Rule Discovery) چکونه توسعه یابد، صحبت می شود. در حقیقت این مقاله قوانین مربوط به پزشکی را از دیتاست مورد نظر در مورد تشخیص هپاتیت مزمن استخراج می کند.
در این مقاله پیش پردازش های زیر انجام شده است:
یکی کردن نام های مختلف به موجودیت های مشابه، یکی کردن چرخه های بازرسی مختلف، گسسته کردن سری های زمانی.
با استفاده از یک چارچوب کلی داده کاوی سری زمانی بر اساس استخراج الگو و درخت تصمیم گیری ، ما قوانین مربوط به ترکیبی از الگوهای نتیجه آزمایش پزشکی را کشف کرده ایم. این سیستم قوانین جالبی از نظر پزشکی کشف کرده است ، و یک متخصص پزشکی دانش خود را با الهام از کشف و ارزیابی قوانین هماهنگ کرده است.
ادامه مطلب ...مراحل اصلی داده کاوی در مدل CRISP
اولین بار در دهه ۱۹۹۰ گروهی از شرکت های اروپایی روش کریسپ را برای انجام پروژه داده کاوی ارائه دادند. این فرآیند دارای شش مرحله اصلی است. این شش مرحله از درک نیازهای اصلی کسب و کار شروع می شود و در نهایت به ارائه راهکاری برای آن ختم می شود. به نظر می رسد که این مراحل به دنبال یکدیگر انجام می شوند اما در عمل رفت و برگشت های زیادی بین مراحل وجود دارند.
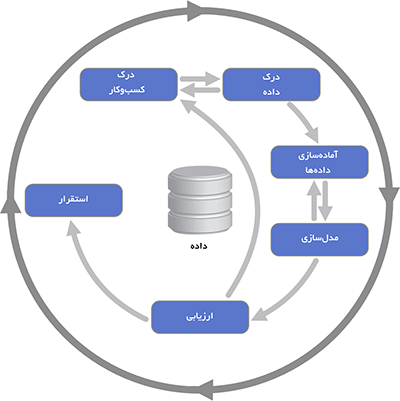
ادامه مطلب ...
یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی (Reinforcement Learning) گونهای از روشهای یادگیری ماشین است که یک عامل یا Agent را قادر به یادگیری در محیطی تعاملی با استفاده از آزمون و خطاها و استفاده از بازخوردهای اعمال و تجربیات خود میسازد.در یادگیری تقویتی، وقتی عامل در یک حالت خاص عملی را انجام می دهد، در مقابل پاداش یا (Reward) دریافت می نماید. در این نوع یادگیری ماشین، تمامی تلاش و هدف عامل این خواهد بود که تا پاداش دریافتی را در دراز مدت به حداکثر برساند. اگرچه هم یادگیری نظارت شده (Supervised Learning) و هم یادگیری تقویتی از نگاشت بین ورودی و خروجی استفاده میکنند، اما در یادگیری تقویتی بر خلاف یادگیری نظارت شده از پاداشها و تنبیهها به عنوان سیگنالهایی برای بهبود عملکرد نهایی سیستم استفاده می شود.
ادامه مطلب ...پیش پردازش داده ها
در ابتدا یک تعریف مختصری از داده کاوی ارائه می دهم و سپس به مراحل پیش پردازش داده ها می پردازیم.
داده کاوی شامل تکنیک ها و ابزارهای میشود که به ما کمک میکند از حجم بالای داده ها ذخیره شده، اطلاعات سودمندی رو استخراج کنیم که استخراج آن ها توسط انسان و تکنیک های ساده پردازش داده غیر ممکن است.
ادامه مطلب ...حل مسئله Maze با استفاده از الگوریتم ژنتیک
maze (میز) به راه های تو در تو گفته می شود، که باید از یک مکان وارد و از مکان دیگر از آن خارج شد. به عبارت دقیق تر، Maze یک ناحیه شبکه ای شکل دو بعدی است که شامل سلول هایی می باشد. یک Maze می تواند شامل موانع مختلف و با هر تعدادی باشد. پیچیدگی Maze بسته به تعداد سلول ها، موانع، راهرو ها و بن بست ها و فاصله بین سلول شروع تا پایان، متفاوت می باشد.

هدف در این مسئله اتخاذ ترتیبی از تصمیمات به منظور رسیدن به حالت هدف از حالت شروع می باشد.
روش های متفاوتی جهت حل مسئله Maze وجود دارد، که الگوریتم ژنتیک یکی از این روش هاست که جواب تقریبا بهینه را بدست می آورد.
در این مطلب قصد داریم حل مسئله Maze را با استفاده از الگوریتم ژنتیک توضیح دهیم. الگوریتم های ژنتیک، روش اکتشافی از دسته الگوریتم های تکاملی هستند که بر اساس اصل داروین و با استفاده از انتخاب طبیعی است. الگوریتم ژنتیک در دهه 1960 توسط "جان هالند" بیان شد.
ادامه مطلب ...