MDM: Medical Data Mining
داده کاوی در پزشکیMDM: Medical Data Mining
داده کاوی در پزشکی
سیستم پشتیبانی کشف قانون برای داده های متوالی پزشکی
مقاله: سیستم پشتیبانی کشف قانون برای داده های متوالی پزشکی - مطالعه موردی دیتاست های هپاتیت مزمن (Chronic Hepatitis)
در این مقاله در مورد اینکه پیش پردازش داده ها چگونه باید انجام شود و یک سیستم پشتیبانی کشف قانون (Rule Discovery) چکونه توسعه یابد، صحبت می شود. در حقیقت این مقاله قوانین مربوط به پزشکی را از دیتاست مورد نظر در مورد تشخیص هپاتیت مزمن استخراج می کند.
در این مقاله پیش پردازش های زیر انجام شده است:
یکی کردن نام های مختلف به موجودیت های مشابه، یکی کردن چرخه های بازرسی مختلف، گسسته کردن سری های زمانی.
با استفاده از یک چارچوب کلی داده کاوی سری زمانی بر اساس استخراج الگو و درخت تصمیم گیری ، ما قوانین مربوط به ترکیبی از الگوهای نتیجه آزمایش پزشکی را کشف کرده ایم. این سیستم قوانین جالبی از نظر پزشکی کشف کرده است ، و یک متخصص پزشکی دانش خود را با الهام از کشف و ارزیابی قوانین هماهنگ کرده است.
این مقاله از پنج بخش تشکیل شده است:
بخش اول: در این بخش در مورد EBM توضیح داده شده است.( EBM یک روش عمل پزشکی است که بر اساس شواهد بالینی حاصل از تحقیقات سیستماتیک است.) و بیان می کند که ارتباط بین داده کاوی و EBM در چند سال گذشته افزایش داشته است و همچنین دیتاست ها دارای مشکلاتی هستند که از طریق پیش پردازش باید آن ها را جهت داده کاوی آماده کرد. ما باید بطور سیستماتیک متدولوژی را برای استفاده از تکنیک های داده کاوی در مجموعه داده های پزشکی واقعی ایجاد کنیم و باید محیط نرم افزاری را برای حمایت از متخصصان پزشکی در کشف دانش پزشکی برای EBM توسعه دهیم.
بخش دوم: توسعه سیستم
بخش 2 مفهوم اساسی و توسعه سیستم پشتیبانی از کشف قانون را توضیح می دهد. باتوجه به اینکه نتایج تست های پزشکی در شرایط و زمان خاصی بدست می آید، در نتیجه زمان در اینجا مهم است و بسیاری از داده های تشخیص عددی هستند، بنابراین تکنیک داده کاوی برای کشف قوانین استخراج از داده های متوالی و عددی برای یک مجموعه داده پزشکی واقعی مناسب است. در این بخش از چارچوبی استفاده شده که از سری های زمانی برای کشف قوانین استفاده می کند.
شکل زیر چارچوب داده کاوی سری زمانی کلی بر اساس استخراج الگو و طبقه بندی را نشان می دهد.

در ادامه ما یک سیستم پشتیبانی از استخراج قانون برای داده های متوالی پزشکی طراحی و توسعه داده ایم که بر اساس چارچوب کلی داده کاوی سری زمانی ساخته شده است. در شکل زیر این سیستم نشان داده شده است. در چرخه این فرآیند، قوانین کشف شده از یک متخصص پزشکی الهام می گیرد و این متخصص دانش جدید خود را به سیستم باز می گرداند.

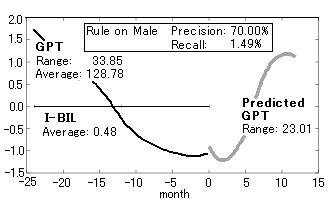
در شکل زیر نمونه ای از قوانینی که در تحقیقات قبلی ما در مورد مجموعه داده های مزمن هپاتیت استخراج شده است را مشاهده میکنید.
بخش سوم: پیش پردازش برای داده های متوالی پزشکی
در اینجا ما از دیتاست های نتایج تست پزشکی بیماران هپاتیت B و C که از بیمارستان دانشگاه Chiba تهیه شده است، استفاده کردیم.
مجموعه داده های خام شامل پنج مجموعه از موارد آزمایش پزشکی بود: مشخصات بیمار ، متا داده های نمونه گیری تشخیصی ، نتایج نمونه گیری تشخیصی ، نتایج بیوپسی کبد و شرایط داروی اینترفرون، که این اطلاعات از 957 نوع آزمایش پزشکی ، 771 بیمار و حدود 1600000 پرونده بدست آمده است.
جهت پیش پردازش داده ها ما از پاکسازی داده، انتخاب موردی، یکسان سازی فاصله آزمایش و درج مقادیر از دست رفته به عنوان پیش پردازش سطح پایین استفاده کردیم. ما نتیجه گرفتیم که گسسته سازی و یکپارچه سازی داده ها به عنوان یک پیش پردازش سطح بالا به دانش حوزه پزشکی بستگی ندارد.
بخش چهارم: مطالعه موردی
این بخش نتیجه استفاده از سیستم طراحی شده در مجموعه داده های مزمن هپاتیت را نشان می دهد.
در این تحقیق ما سه قانون بدست آوردیم که آن ها را به متخصصین پزشکی دادیم و نظرات آن ها را اینگونه دریافت کردیم: دو تا از قوانین بدست آمده باارزش و یکی عجیب به نظر می رسد. که با بررسی قانون سوم متوجه شدیم که اختلاف بین داده های خام و الگو خیلی زیاد است.
بخش پنجم:نتیجه گیری
بخش 5 این مقاله را به پایان می رساند و کارهایی که در آینده قرار است انجام دهند را توضیح می دهد.